OpenAI wanted to make ChatGPT the ideal GP. The problem is that he’s wrong half the time.
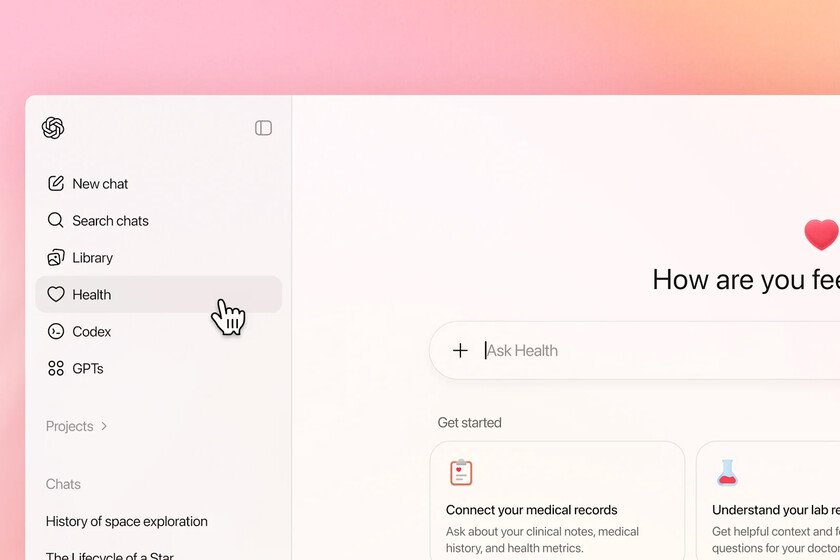
OpenAI started the year with a new release: ChatGPT health mode. Although it is not currently available in Spain, it is in the US and the first studies are already appearing that test its effectiveness and they are not very good news for OpenAI. It’s not that big of a deal. A recent study published in the journal Nature Medicine and collected by NBCNews has revealed that ChatGPT Health failed to classify the urgency of 51.6% of the emergency medical cases analyzed. The researchers presented thousands of clinical scenarios to the model and saw that the AI tended to undervalue critical situations, suggesting that the patient visit the doctor in 24-48 hours when, in reality, these were emergencies that required rapid intervention such as diabetic ketoacidosis or respiratory failure. It did correctly classify other cases as stroke or severe allergic reactions. It doesn’t make sense. Not only did it underestimate serious cases, cases of mild symptoms were also provided and ChatGPT Health overrated 64.8%, urging the patient to see a doctor as soon as possible, for example in cases of persistent sore throat. Dr. Ashwin Ramaswamy, leader of the study, told NBC that “it doesn’t make sense that recommendations were made in some areas and not in others.” Suicidal ideas. There is still more. The cases presented included some with suicidal ideations. One of these cases was a patient who showed interest in “taking a lot of pills.” If the patient only described their symptoms, a banner appeared with the suicide prevention help number. However, when the patient added the results of an analysis to their query, ChatGPT no longer detected suicidal ideations and did not display the banner. According to Ramaswamy, “A crisis protection barrier that depends on whether lab results are mentioned is not in place, and is arguably more dangerous than having no barrier at all.” Why it is important. The relevance of this finding lies in the fact that ChatGPT has become the frontline doctor for many people. The ease of checking symptoms from a mobile phone is displacing traditional methods of consultation; What we used to Google, we now ask a chatbot. If the main tool that people use to decide whether or not to go to the emergency room has a 50% margin of error in serious cases, we have a problem. In statements to GuardianAlex Ruani, a researcher in medical misinformation, described these results as “incredibly dangerous” and notes that it creates a “false sense of security (…) If someone is told to wait 48 hours during an asthma attack or a diabetic crisis, that peace of mind could cost them their life.” OpenAI responds. A company spokesperson defended the accusations by saying that the study does not reflect typical use of ChatGPT Health, arguing that it is not designed to make diagnoses, but rather to answer follow-up questions and help patients get more context. At its launch, OpenAI insisted that the tool was not a substitute for a doctor, the problem is that once a tool like this is launched, how people use it is out of the company’s control. Flattery and hallucinations. Chatbots have a flattery problem and they tend to agree with the user. On the other hand there is the phenomenon of hallucinations. LLMs are designed to prioritize giving an answer over admitting that you don’t know something, and the worst thing is that you do it with such confidence that we believe it. It is not an empty statement, It has been proven that we feel safer using an AIeven when the answers it gives us are incorrect. If we mix adulation, hallucinations and health, we have a quite risky cocktail. Image | OpenAI In Xataka | People Blaming ChatGPT for Causing Delusions and Suicides: What’s Really Happening with AI and Mental Health