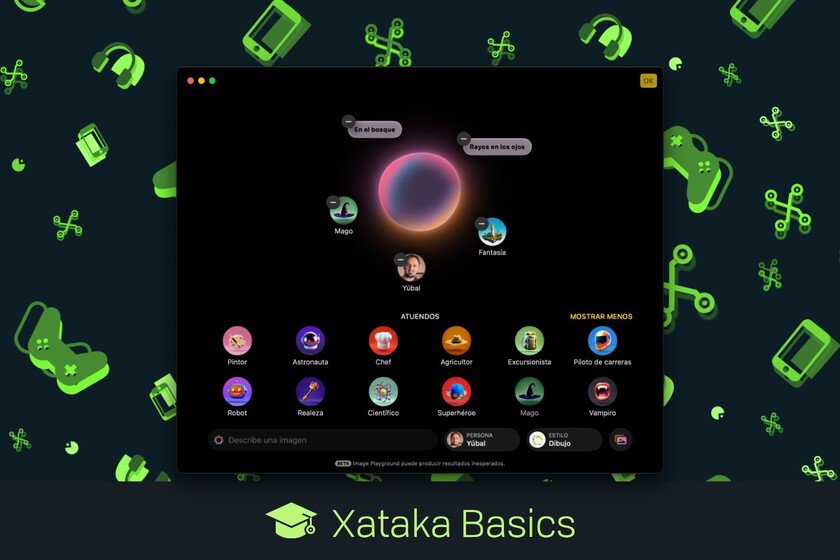
We have tried to use AI to verify if the images of the war between Iran and Israel were made with AI. It has been a disaster

False images circulate on social networks is no novelty, but in the era of AI It is increasingly difficult to detect them And they have even made Let’s distrust real photos. That photos taken with AI are viral when an important event is the new normality is; We saw it After the blackout And also with him Conflict between Israel and Iran. It is clear to us that AI is very good to generate false images, but what if we use it precisely for the contrary? Not so much. The photos in question. At the same time as a Half Iranian published The news that Iran had demolished an Israeli F-35, two images began to run like gunpowder on social networks, although We soon knew they were false. One of them, that of the star and surrounded by curious F35, is especially striking. To begin with, the proportions make no sense: the plane seems giant when actually measures 16 meters and people are larger than buildings. And that not to mention that the damage of the plane is minimal to have been shot down. These images were not the only ones generated by AI that circulated in the first days of the conflict. Several videos such as this one of a huge Iranian missile that it seems quite real until we see that the water brand has been left to see that it is made with the, or East of a tel aviv shattered. AI is terrible doing FACT-CHECK. Means dedicated to FACT-CHECKING as Damn already denied These and other images created with AI in the context of the conflict between Iran and Israel. However, there were users who tried to resort to AI tools to check the authenticity of the images and obtained quite confusing answers. Is What happened in X with Grok. An analysis of more than 130,000 posts revealed that Musk’s AI was not able to detect some false images or identify the sources from which they came. The community notes written by the users themselves were much more reliable. We have tried it. To check the AI capacities, we have used the image of the disproportionate F-35 and have asked several AI tools. This is what they have answered: Chatgpt: The Openai tool begins “This image does not seem real” and then proceeds to make an analysis of the proportion of the plane, which correctly identifies as a F35, and states that the damage does not seem coherent. Perplexity: Like Chatgpt, he tells us that proportions, perspective, and airplane damage and other details suggest that the photo has been digitally manipulated. Gemini: It tells us that the image is real, but that it is not an attack in combat, but of a clash with birds that happened in Israel in 2017. When we answer that the sources show us, it happens several links to the news, but in none of them the image appears. After a while sending us confusing information, he ends up recognizing that he was wrong and apologizes for “the serious mistake.” Claude: It is the only one that states with forcefulness that the image is not real and gives us the exact context of what has happened “this is one of the many false images that have circulated as part of misinformation campaigns during the conflict between Israel and Iran.” The reliability, pending subject. In our test, Gemini has completely invented the answer, while Chatgpt and Perplexity succeed, although they do not get wet. Claude is the only one that gives us all the information and hits fully. Although language models have improved a lot in a short time, Many answers continue to be invented Despite having access to the Internet and searches. Undoubtedly, reliability is the pending subject of generative AI and where more improvement margin has. Images | 404 average In Xataka | Chatgpt guide: 22 functions and things you can do to squeeze this artificial intelligence to the maximum