
You may not have stopped to think about it, but there is a striking reality in the world of chatbots: It is more expensive to speak in Spanish with AI than to do so in English.
The reason is simple: AI does not understand words, it understands tokens. And when you talk to GPT, Gemini, Claude or any other LLM, you talk to him in a language, but to understand you he first “translates” what you are telling him and converts it into tokens. And the problem is precisely that: that not all languages ”cost” the same in terms of tokens.
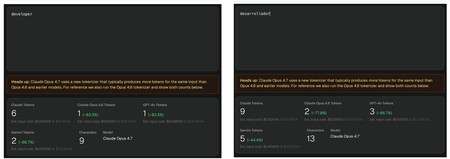
There is a very simple example that we can analyze thanks to tools like ClaudeTokenizer: the word “developer”, which in English is “developer” costs few or many tokens depending on the language in which we write it and also (importantly) the version of the AI model used. In the image it is clearly seen, but just in case, we summarize:
- For ChatGPT (GPT-4o and GPT-5) the word “developer” has three tokens (des-developer-ador), but the word “developer” only costs one.
- For Claude (Opus 4.7) the word “developer” costs no less than 9 tokens (2 in Opus 4.6), but “developer” costs “only” 6 (1 in Opus 4.6).
What is happening here?
Well then each language model uses its own “tokenizer”your “translator” from a conventional language to the token language that the language model understands. And those tokenizers favor precisely the languages in which these models are created.

This is how AI understands how we speak. Each word is divided into tokens, and English is understood much better. “developer” only costs one token in GPT-5, but “developer” breaks down into three. Bad news for Spanish speakers.
In fact, English has become the official language of artificial intelligence, whether we want it or not. The reason is not cultural, but architectural: 95% of the training data of the frontier models (GPT-5, Gemini 3.1, Claude Opus/Sonnet 4.7…) are in that language.
That makes the rest of the languages ”foreign languages”, and that makes it necessary to pay extra when using them, an almost invisible toll on every interaction. In practical terms, what happens when we use Spanish to talk to an AI model is simple: we use more tokens, and therefore using Spanish is simply more expensive than using English when working with a large language model.
If you want to save tokens, better use English
The question, of course, is how much more does it cost us to speak in Spanish than in English with ChatGPT (GPT 5.x) or with Claude Opus 4.7?
It is difficult to say because each word and each phrase is a world, but the truth is that English is almost always the most “economical”. We have used one of the first sentences in this article to compare that token consumption, and by translating the sentence into different languages and querying that token consumption for different models, the data is clear.

It is important to highlight that these results are not conclusive, but they do make the trend clear: English is the most efficient language in terms of token consumption, but be careful, because Spanish is not that bad, and is usually the second most efficient. It is even more efficient than English in Gemini, at least according to the tool consulted.
But on average, it is normal that there is a significant extra cost when using different models. A conversation with Claude Opus 4.7 is already “expensive” because it is one of the most expensive models currently, but in Spanish it is almost 30% more expensive, not to mention in Arabic, 76.3% more expensive.
In fact, according to this example, the difference between Claude or GPT-4o in terms of efficiency is clear: OpenAI tokenizer is “cheaper”and although there may be differences with GPT-5.x, what seems clear is that Anthropic has preferred to “spend more” to obtain better results (or that is the objective). Gemini is even more thrifty according to these tests, and that may also have a lot to do with the quality of the answers, although that question is for another topic.
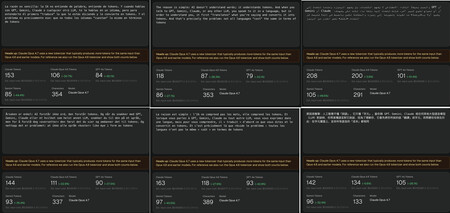
We have used one of the paragraphs of this article in Spanish and translated it with Deepl into English, Arabic, Norwegian, French and Chinese to find out how many tokens the phrase “cost” in each language. English is undoubtedly the most efficient
Tokenizers advance and evolve. Sometimes they do it to save us tokens, as happened with the GPT-4o tokenizer: at that time OpenAI explained how that tool used 1.1 times fewer tokens when speaking to her in Spanish but up to 2.9 times fewer in Hindi or 3.5 times fewer in Telugu. With Claude Opus 4.7, just the opposite has happened: the tokenizer has been redesigned and consumes more tokens (up to 1.35 times more, they admitted) with the aim of better processing and understanding the text.
Your chatbot thinks (and programs) in English
Here we must also highlight something important: although we can talk to our favorite chatbot in any language and it will answer us in that language (unless we ask otherwise), AI models “think in English”.
That is to say: when you talk to them what they do is translate what you tell them and then reason in English and finally they translate their response into the language in which you were speaking to them. This consumes additional reasoning tokens, but also has some impact on latency (how long it takes to start thinking or answer the model). In complex tasks, this can clearly influence response times for the simple reason that the AI model does not stop translating from “its official language” (English) to our language.
This preference for English is also noticeable in the benchmarks: in the Humanity’s Last Examin which the models are asked all kinds of general knowledge questions with several options to answer, it is reasonable to think that the models They answer better in English because that exam is designed in that language.

In programming tasks, this use of English also favors results. There is specific studies that deal with the topic and make it clear that if you are using AI to program, it is not a bad idea to “speak” to it in English directly. The reason remains the same as we had mentioned: the vast majority of programming training data precisely They are in English because this was already the de facto “official language” of the programmers before AI appeared.
There are also various studies that confirm for years that English is the most efficient language when conversing with AI models, but they also pointed out how better supporting multiple languages can help make multilingual use not only feasible, but efficient.

In this study June 2025 by Microsoft researchers, the authors indicated precisely that: “multi-language prompting can reduce token usage by 20 to 40% without compromising accuracy, providing a simple and effective strategy to improve inference efficiency without the need for retraining.”
In that study, models such as Qwen or DeepSeek were used to indicate that reasoning in Spanish or Chinese could be more efficient, but be careful, because we insist: each model is a world and logically the models developed in the US have an absolute preference for English in terms of training data.
But then, do I use English or can I continue in Spanish?
If one looks at that data, the conclusion seems clear: if we can, we should speak to the AI in English directly. The reality is somewhat different.
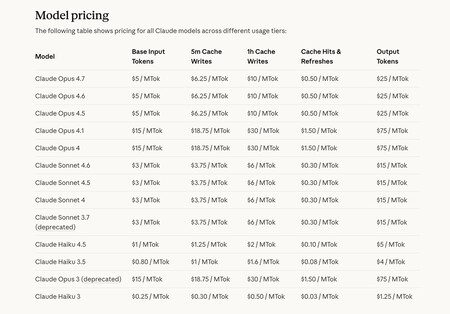
When you use AI models through APIs (you pay what you use), perhaps it is not a bad idea to try to use English to talk to these models. In the image, the prices for different Anthropic models.
Above all, because the prices for using AI do not stop falling and that makes the extra cost of using tokens used when speaking Spanish probably irrelevant for domestic use. Not only that: most users take advantage of monthly plans like ChatGPT Plus either Claude Pro (for example), and in those plans we have a kind of “pseudo flat rate”.
These plans are not unlimited, of course, and if we use them intensively we will encounter the dreaded “sorry, you will have to wait until five hours from now to continue using this model.” However, reaching these limits is difficult for moderate use, and here using the models in English or Spanish is not too important.
It is true that in some areas using English has advantages, not only in terms of efficiency (tokens “last” us longer), but also in terms of precision. This can happen in more complex tasks such as programming, and there using prompts in English can help obtain results that perhaps we cannot obtain in Spanish or other languages.

The things They change a little if we use AI models through APIs of these platforms. There are no flat pseudo-rates here, and you pay for what you use, so saving on tokens can be important especially if we are intensive users (and if we use APIs it is usually because the models are used especially intensively). There it may be interesting to use the models directly in English, because we will clearly notice this in our pocket.
In Xataka | The “token economy” is broken: flat AI programming fees are mathematically unsustainable
GIPHY App Key not set. Please check settings