
The arrival of DeepSeek-V4-Pro It hasn’t caused that much of a stir. like the one caused by DeepSeek R1 a year and a half ago, but we may be facing an even more important model. If that version revealed to the world that China was advancing spectacularly in this race, this other one is beginning to allow us to glimpse something else more interesting. What most people see is a very decent model and above all “low priced”. Which hide the company It’s another more important thing: achieve independence from Nvidia and US hardware.
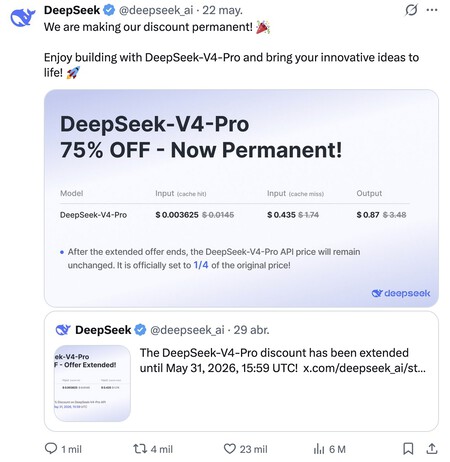
what has happened. Last Friday, those responsible for DeepSeek announced something surprising: their promotional offer with a 75% price cut to use their DeepSeek-V4-Pro model will be maintained permanently. That makes this model offer very decent features (but not exceptional) for a really low price:
|
1M entry tokens |
1M tokens output |
|
|---|---|---|
|
DeepSeek-V4-Pro |
0.435 |
0.87 |
|
GPT-5.5 |
5 |
30 |
|
Opus 4.7 |
5 |
25 |
|
Gemini 3.5 Flash |
1.5 |
9 |
Good, pretty and very cheap. It is true that the performance of DeepSeek-V4-Pro is inferior to that of rival models from OpenAI, Anthropic or Google. Artificial Analysis tests indicate that the DeepSeek model is at a very good level, but it is also much cheaper than its competitors. This is especially relevant for agentic tasks that consume many tokens and that with this model become accessible and very affordable.
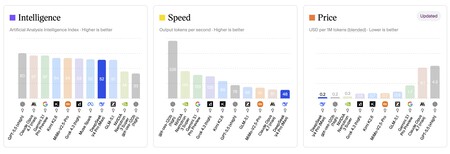
According to Artificial Analysis, DeepSeek is close to the performance of the best models in the industry, and although it is slower in its responses, it is also much cheaper than the frontier models from OpenAI, Anthropic or Google.
A different strategy. How is this company going to make money? It does not have subscription plans like its local competition (GLM, Kimi) or the western one (ChatGPT Plus, Claude Pro). It also does not have voice or image models. It does not have an AI agent for programming that competes with Claude Code. It publishes the open weights of its models and shares its technical innovations with the industry (and with its competitors). For those who closely follow the company and these decisions, the strategy is clear. DeepSeek’s goal is not to win the AI model race. Their goal is to build a Chinese AI hardware industry that doesn’t depend on Nvidia or TSMC… and get paid their share in that process.
Hardware independence. China has a structural problem in this AI race: sanctions and vetoes imposed by the US make you unable to access the most advanced chips nor to ASML UVE photolithography. And since China cannot currently compete in terms of computing power, what its companies are doing is ensuring that their AI models need less computing power to achieve similar results.
Efficient architectures. The Mixture of Experts (MoE) and Multi-head Latent Attention (MLA) architectures are two key weapons in this strategy. The first already existed but was adapted by DeepSeek for their model: with it only part of the total parameters of the model are activated to answer the query without losing precision. What MLA does is compress the attention information (the so-called KV Cache) with which the model maintains the context of a conversation, reducing it by 90%. Both techniques allow us to reduce the need to use high-speed HBM memories, something that is also striking in order to reveal DeepSeek’s probable strategy.
The importance of KV Cache. As the GDP analyst explains in Xthat use of MLA allows that for one million tokens, DeepSeek-V4-Pro only needs 5.48 GB of HBM memory. Competitors like Zhipo AI, which develops GLM 5, need 60 GB for the same, while Alibaba’s Qwen 3 needs 89 GB. This advantage allows DeepSeek to offer much lower prices to obtain performances similar to those of its competition, but it also means that DeepSeek models can run on Chinese memory chips that cannot compete in speed with HBM modules.
Goodbye HBM, hello NAND and SSD. These innovations open the door to the use of NAND memories and even SSD drives to process this data, and there YMTC enters the scenea Chinese Flash memory manufacturer that is slowly becoming a global giant. Also CXMTwhich manufactures DRAM memoriesbecomes an alternative here and the reason is equally interesting: DeepSeek introduced a memory search module in LLMs called Engram which is also intended to avoid excessive dependence on HBM memories.

How to bypass the CUDA monopoly. Nvidia continues to have a fundamental element in CUDA to maintain its market dominance, but here DeepSeek too has proposed an alternative. Is called Tile Kernels and these are software cores created with TileLang (a variant of Python for this field) that allow governing advanced AI chips (GPUs).
Huawei as an invisible ally. Those responsible for Huawei recently indicated that its new Ascend AI supernodes fully support DeepSeek v4 models. Precisely this provides another fundamental advantage to the company, which thus avoids (at least in part) total dependence on the use of Nvidia chips and prepares to further strengthen Huawei’s relevance in a market in which until recently Jensen Huang’s company was queen and mistress.
Open models to attract the hardware industry. US companies continue to maintain their closed and proprietary models, but DeepSeek is one of the many Chinese startups that publish them with open weights. With this, what she and the others intend to do is not only attract AI developers and users, but also create a hardware ecosystem that adopts these architectures. DeepSeek invites its rivals to use techniques such as MoE or MLA precisely so that all these advances become a de facto standard and hardware manufacturers also adopt them and integrate them in an optimized way into their designs.
A round of 10,000 million to advance. The company is also preparing a financing round in which they intend to raise 10,000 million dollars and with which they would achieve a valuation of between 45,000 and 50,000 million dollars. Still far from the mammoth valuations of OpenAI or Anthropic (already close to a billion dollars) but certainly extraordinary for a Chinese startup. With that money they will have many more options to continue strengthening this strategy.
GIPHY App Key not set. Please check settings