During the last three years the models of artificial intelligence (AI) have improved a lot. Often the latest reviews of ChatGPT, Claude, Gemini or DeepSeek provide us with convincing answers to the questions we ask them or the tasks we ask them for. However, your first answer is usually not the best. It almost never is. If we settle for the first thing they tell us We will be underusing them and wasting part of their potential.
Fortunately, there is a very simple strategy that can help us not to obtain a reasonably good answer, but to achieve the most accurate and reliable result. The optimal response. And it consists of chaining several AIs so that each one of them refines the work of the previous one. When we ask an AI for something, the model generates a response based on the context we have given it. If the context is scarce, the response can clearly be improved.
Now, if the context is well defined but the request is broad, the AI will tend to cover the ground in a reasonable way, although without delving into any specific aspect. No professional work is delivered in its first version. There is always a review, a criticism or an adjustment. The chaining of several AIs transfers exactly that logic to working with language models. And, as we are about to see, it is a very valuable ally.
What is chaining multiple AIs and why does it work?
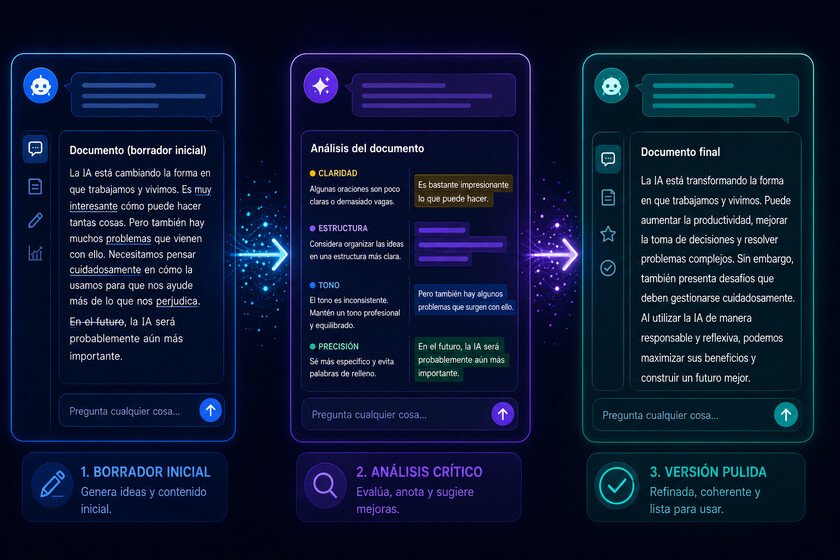
What we propose to do is simply use the output of one AI model as input for the next one. Instead of asking an AI to do everything in a single step, we can divide the work into several phases. In this way, one AI generates the first result, another criticizes it, another refines it and a last one verifies everything. In this scenario, each model acts as a specialist with a different role. And the final result accumulates the advantages of each phase.

It is important that we keep in mind that language models respond to the immediate context they receive, and not to an abstract objective. It is not that one AI is necessarily better than another. Our starting point is that a model that we ask exclusively to criticize a text is more effective than one that we ask to generate it and criticize it at the same time. Specialization improves the result.
A model that we ask exclusively to criticize a text is more effective than one that we ask to generate it and criticize it at the same time
Be that as it may, the ideal is that we illustrate this strategy with a practical example. Let’s imagine that we need to write a delicate email in which we intend to reject a collaboration proposal without damaging our professional relationship with the person to whom we are going to send the email. We can ask ChatGPT for the following:
“Compose an email to reject a collaboration proposal from a supplier with whom I have a good relationship. I want the tone to be cordial, leave the door open for future opportunities and not sound like an excuse”
The result will be a perfectly valid email. Maybe too generic, but valid. To improve it we can copy that text and give it to Claude with a prompt like this:
“Act like a professional communication expert. This is a rejection email I wrote. Identify your three weakest points and explain how I can improve each of them”
Claude will point out, for example, that the opening is too abrupt, that the phrase “leave the door open” sounds like an empty formula, and that the closing does not propose any concrete step. However, we are not done yet. Now we can polish it up a bit more by handing Claude’s output to Gemini, or even ChatGPT, with a prompt like this:
“Rewrite this email incorporating the following improvements: (here we paste the three points that Claude criticized). Keep the same tone and length”
Investing two more minutes in chaining three prompts instead of using just one can transform a correct result into an exceptional one.
The result of this third step will be substantially better than the first. Not because no AI is more “intelligent” than the others, but because each of them has acted with a very delimited purpose. In any case, it is not essential that we resort to various AI models. We can also do the same with a single AI if we change the role in each message.
Our strategy is the same: we will not ask a single prompt let him do it all. We will generate first, critique later, and refine last. We can even add a fourth verification step (“Is there anything in this text that could be misinterpreted?”) or adaptation (“translate it now into a more informal register”). Each additional step has a low cost and a high benefit. Invest two more minutes in chaining three prompts Instead of using just one, you can transform a good result into an exceptional one.
Image | Generated by Xataka with a prompt created by Claude and submitted to ChatGPT
In Xataka | ChatGPT blocking mode: what it is, what it is for, who can use it and how to activate it
In Xataka | AI is replacing one of the most hated jobs in the world: the tailcoat collector
GIPHY App Key not set. Please check settings