In order for ChatGPT, Gemini or Meta AI to respond well to the enormous number of questions that their users ask every day, years before the companies behind them made a decision: to obtain data at all costs and from wherever. Books, newspaper articles, song lyrics, illustrations, source code. Its premise was clear: it was Better to ask for forgiveness than to ask for permission.
So today the courts are full of lawsuits, billions of dollars at stake and the AI business model in the dock. For years, piracy was a matter of individuals downloading movies. Now it is the largest companies in the world that have done something similar, but on a large scale and with technology that structurally violates it. What the judges decide will mark how artificial intelligence is built from now on.
Just as you prepare better for an exam if, in addition to taking the class book, you go to the library and read recommended books and expand with other readings associated with the topic you are reviewing, the different research teams behind the great AI models. it occurred to them that with huge datasets and from varied sources the result was better. The problem is that that tremendous volume of data does not fall from the sky: They took it from the web, from digital libraries and from LibGen or Z-Library repositories. The usual defense of companies like OpenAI is fair use and text and data mining exceptions, ensuring that they use unlicensed data legitimately. So the courts go case by case.

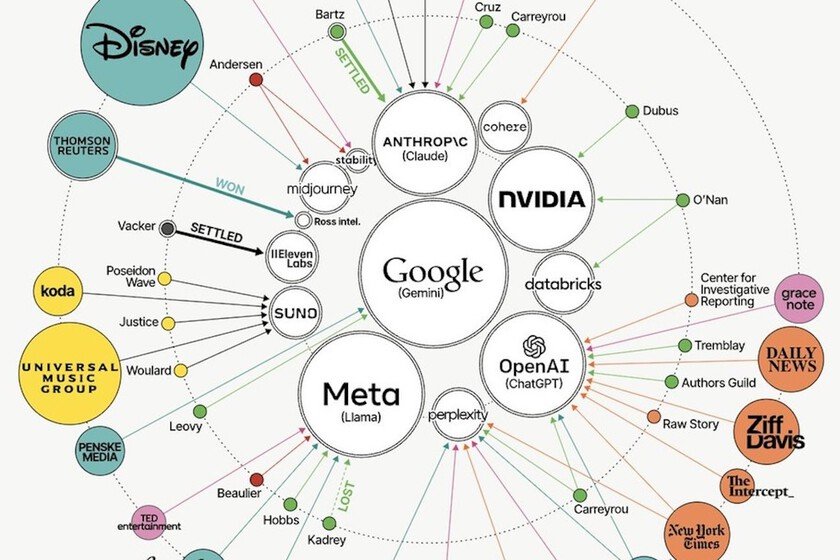
Whether or not training AI models with protected content is fair use is the most important copyright question the courts have faced. Depending on the result, companies face a dark future: the payment of licenses retroactively, cleaning databases and of course, changing how they collect your data from now on. And they have lawsuits to bore: more than 100 active complaints in June 2026, according to the graph.
It is important to note that this chart refers only to United States courts. Furthermore, in Europe it is a different story. The old continent has more restrictive regulations: it requires deleting data after use and allows creators to reserve their rights. The AI Act requires publishing what data was used in training, something that companies have consistently avoided.
The graphic in question is the work of David McCandless for Information is Beautiful and has been prepared using data from ChatGPTisEatingTheWorld.com, Wired reports and reference news. And his work is commendable: talking about litigation is not easy, but he has managed to synthesize it in a single graph to know who sues who in the world of AI.
In the center are the technological companies in demand and on the outside, those who demand: from writers to media, platforms and artists. Each category is represented with a color and the larger the circle, the larger the company. There is also a disclaimer: to make the graph look better, when a plaintiff has several open lawsuits, only the main defendant’s lawsuit is shown. Come on, there are many more than we see.
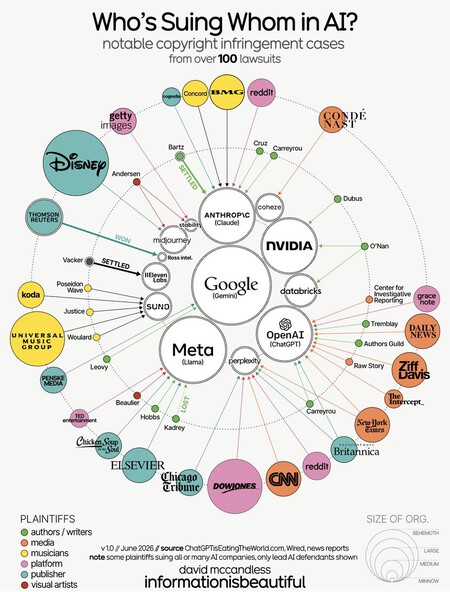
Who is suing who. Information is beautiful
The map of conflicts
On one side, the companies that built AI models, such as OpenAI, Google, Meta, Anthropic, NVIDIA and Perplexity, among others. To another, plaintiffs of all kinds who allege that their works were used without permission or compensation to train systems that have now become their competition. The bottom line is that all the major AI companies are receiving requests from almost all creative categories. Some great cases:
- Bartz vs. Anthropic. The company led by Dario Amodei agreed to pay $1.5 billion after it was shown that it had downloaded hundreds of thousands of books from unofficial repositories. The court validated the training as fair use, but not the way to achieve it.
- Kadrey vs. Goal. Mark Zuckerberg’s company won in the training part, but is still on trial for having distributed pirated content.
- New York Times vs. OpenAIstill in progress. The Times alleges that ChatGPT reproduces its articles almost verbatim, replacing the original source.
- Disney vs. Midjourneystill in progress: The big entertainment studios fight against the generation of images.
- Concord, BMG and Universal vs. Anthropicstill in progress. The big legendary record labels sue for reproducing protected lyrics.
The US Copyright Office public In May 2025, a 108-page report concluded that there is no universal answer: determining whether the use of works to train AI is fair use requires analyzing each case separately. And not all companies are the same nor are all uses.
What is clear is that this system of “asking for forgiveness instead of permission” has a price: Anthropic has shown that it can get away with paying $1.5 billion because its valuation is $183 billion. So the short answer is that today, it has been worth it. The underlying question is whether there will continue to be a flood of lawsuits or whether clearer rules will be established on the use of data and there will be someone with a firm hand and knowledge to apply them.
In Xataka | Who is really winning the AI race, in a graph that puts Google in trouble
GIPHY App Key not set. Please check settings