
A few days ago, the Chinese startup Zhipu AI (Z.ai) announced the launch of its new open AI model, GLM-5.2. It did so boasting amazing features that brought it very close to the best closed models from OpenAI and Anthropic, something that seemed impossible. Well, the more analysis is carried out on the model, the better off it is. We may be at the beginning of something very important. A change of trend.
GLM 5.2. The Chinese startup Z.ai has been releasing different versions of its GLM AI model for a long time, but the latest one is undoubtedly the most surprising because its performance is especially promising. It has 744,000 million parameters (744B), of which 40,000 are those that remain active. We are looking at a model with a context window of one million tokens and a new architecture called IndexShare/IndexCache.
Better than GPT-5.5, very close to Opus 4.8. The startup showed how the performance of GLM-5.2 is extraordinary in programming tasks. In the FrontierSWE test, the most demanding of those currently available, GLM-5.2 outperformed GPT-5.5 and only Opus 4.8 was superior by a very small margin. The same happened with other tests such as PostTrainBench or SWE-Marathon, which, for example, evaluates the behavior of the model in very long autonomous programming sessions.
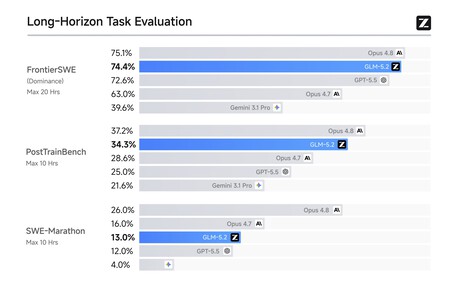
Source: Z.ai.
In many other tests the photo was identical: the model has made a spectacular leap since version 5.1, and is in many tests almost as good (or better) than the best from OpenAI, Anthropic or Google.
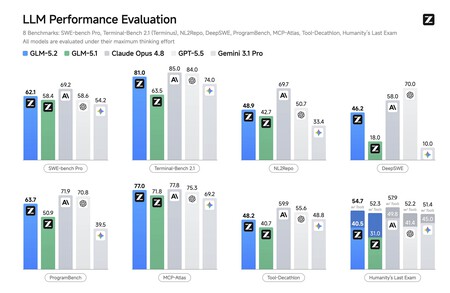
But it’s not just them who say it.. Artificial Analysis, a reputable independent firm that maintains an updated ranking of the performance of the new AI models that are arriving on the market, confirms the data of Z.ai itself. In his tests he indicates how the “intelligence index” of GLM-5.2 is now 51 points. It is only surpassed by GPT-5.5 (55), Claude Opus 4.8 (56) and Claude Fable 5 (60).
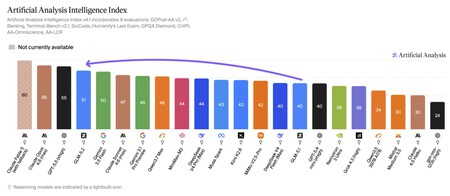
Source: Artificial Analysis.
This Chinese open model leaves behind the new Gemini 3.5 Flash, but also Chinese competitors such as Qwen 3.7 Max, MiniMax-M3 or DeepSeek V4, among others. The jump in quality from GLM-5.1 is, we insist, outstanding, much greater than what, at least according to this index, was seen from Opus 4.8 to Fable 5.
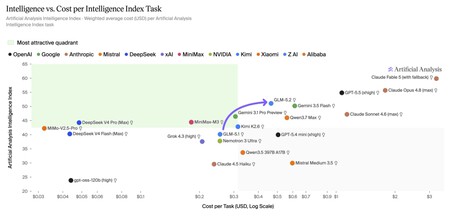
The jump in performance is spectacular, although it is true that the comparative price to solve the tasks proposed in the benchmark rises significantly. Source: Artificial Analysis.
But it’s not perfect. The Artificial Analysis report, however, shows that although GLM-5.2 is very strong in areas such as programming, it is weak in others. For example, it is far from being as reliable as Fable 5, GPT-5.5, Claude 4.8 or Gemini 3.1 Pro in terms of correct answers, which is also lower in proportion to that of its competitors. However, his hallucinations have significantly reduced.
And it’s much (much) cheaper. But in addition to being fantastic in many areas, it is much cheaper than its competitors. Maintains the price per million input/output tokens of its predecessor ($1.4/4.4), while that of GPT-5.5 It’s 5/30 dollars and that of Opus 4.8 10/50 dollars. It is true that it consumes many more tokens than GPT-5.5 (very efficient) or Claude Opus 4.8, but even with that its final cost is much lower.
My tests with GLM-5.2 programming. I’ve been a Z.ai subscriber for months now because they offered an annual subscription at the end of 2025 at a really low price. This has allowed me to test GLM-5.2 for a few hours and although I cannot draw definitive conclusions, it does seem clear that there is a leap in quality in terms of its ability to program. I asked him to review a personal code project and he identified several security flaws and possible improvements in great detail.
Chatting with GLM5-2. In conversational mode the behavior is much more difficult to evaluate: I have been interacting with the model and asking it questions, and although it is better than GLM 5.1 many times, other times it is not so much and I would say that in terms of creativity to write the frontier models of Google, OpenAI and especially Anthropic they are still quite superior. You can try it on their websiteand there you will see something else: it takes significantly longer to respond than other chatbots, because its reasoning phase is longer. Take more time to answer questions.
Benchmarks are one thing, experience is another.. In the absence of testing it (much) more, of course the impression is that the model has improved significantly compared to a GLM-5.1 that had lagged behind its Chinese competitors (not to mention the current Claude Opus 4.8 or GPT-5.5). On platforms like Reddit opinions are dividedbut many consider it a fantastic option to run locally… if you have a very, very powerful machine with at least 256 GB of unified memory (Mac Studio). And one thing seems clear: when using it as an AI model for programming, comes surprisingly close to Claude Opus 4.8.
In Xataka | Chinese technology companies entered the AI race with cheaper models than the rest. That’s starting to end
GIPHY App Key not set. Please check settings