
They have passed 484 days since that “DeepSeek moment“, but the wait It seems to have been worth it, because we have the new DeepSeek V4 with us. We are facing an absolutely gigantic open weights model that once again promises to crack the foundations of the proprietary foundational models of Anthropic, OpenAI or Google. This is moving, gentlemen.
Gigantic and open. DeepSeek v4 is an Open Source model and comes in two versions. The first is the Pro, with 1.6 trillion parameters (1.6T), of which it has 49,000 million active. The second is Flash, with 248,000 million parameters (248B, huge for a “Flash” model) of which 13,000 are active.

More efficient than ever. Both versions they make use of a Mixture-of-Experts (MoE) architecture, which means that only a fraction of the parameters are activated in each inference. This allows the computational cost to be reduced significantly. Both versions support a context window of one million tokens—to include novels and novels at once as input—when in v3 it was 128,000 tokens. Furthermore, this model is much more efficient than its predecessor in computing per token: it requires only 27% of the operations per token and 10% of the KV cache compared to DeepSeek v3.2.
Benchmarks promise. DeepSeek’s internal testing reveals that v4 Pro-Max (the best model with the highest reasoning ability) outperforms or is on par with Claude Opus 4.6 Max, GPT-5.4 xHigh, Gemini 3.1 Pro High, Kimi K2.6 and GLM 5.1. The results, however, are not independently verified, which means we should take them with caution.
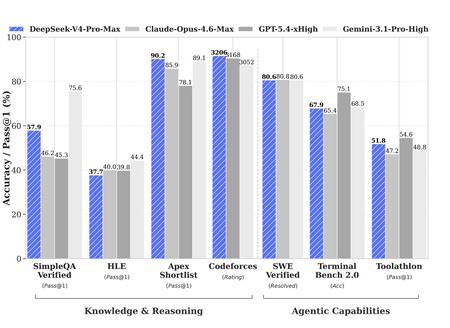
The numbers are still striking: in LiveCodeBench, a programming test, DeepSeek v4-Pro-Max achieves a 93.5% score compared to 88.8 for Opus 4.6 and 91.7% for Gemini 3.1 Pro. In other tests there is more variability, but at least on paper DeepSeek v4 Pro seems as good as Opus 4.7, which until now was the absolute benchmark.

Much cheaper. But as happened with its previous version, the difference in price with those models from US companies is astonishing. As point the analyst Simon Willinson, the official prices of DeepSeek v4 Pro are 1.74 dollars per million input tokens and 3.48 dollars per million output tokens, up to almost seven times less than those of Opus 4.7 and up to almost 9 times less than those of the new GPT-5.5. With DeepSeek v4 Flash the cost is 0.14/0.28 dollars per million input/output tokens, when GPT-5.4 Mini costs up to 16 times more. The conclusion is obvious: if it really does what it says it does, the price is an absolute bargain. That is precisely the challenge: that real experience confirms what the benchmarks say.
The hardware mystery. DeepSeek has not revealed what hardware has been used to train this version of its founding model. In the past they did admit that they had used NVIDIA’s H800s. Which yes it is known The thing is that the model has been developed to run on both NVIDIA and Huawei Ascend chips. This last has confirmed Baidu that its Ascend Supernode clusters based on the Ascend 950 will fully support DeepSeek v4 versions.
Huawei support is “horrible” news for the US. In The Information they already commented that one of the reasons for the “delay” in the appearance of this model was to adapt it so that it worked without problems with Huawei chips. That support is according to Jensen Huang “horrible” news for the US, because it means that dependence on NVIDIA chips no longer exists or at least is reduced to a minimum.
But. The launch comes at a difficult time for the company. Guo Daya, one of the people responsible for the v1 and v3 models, has signed for ByteDance to work on AI agents. Luo Fuli, who led the development of v2, joined Xiaomi last year. This launch also coincides with DeepSeek seeking external funding for the first time. They are expected to raise about $300 million and obtain a valuation of about $20 billion. according to The Wall Street Journal.
From the surprise effect to the continuity effect. The launch of DeepSeek R1 in January 2025 was surprising because it demonstrated that China could train competitive models at a fraction of the cost of Western models. With DeepSeek v4 that surprise effect disappears to give way to the continuity effect. This model seems to maintain precisely what made the previous model famous: extraordinary power at a very low cost.
Bad news for Anthropic. Such low prices are terrible news for Anthropic, which in recent weeks has been forced to execute a kind of “reduflation” of their new modelswhich are not more expensive but consume many more tokens. We’ll have to see if DeepSeek v4 Pro is as good as the company promises, but if it is, we’ll have another “DeepSeek moment” before us. Maybe not as notable as last year’s, but equally relevant.
In Xataka | DeepSeek promised them happiness as the great Chinese AI. I didn’t count on a small detail: Kimi
GIPHY App Key not set. Please check settings