
When ChatGPT broke out in November 2022, OpenAI seemed unrivaled. And, to a large extent, that was the case. That chatbot, despite its errors and limitations, inaugurated a category of its own. However, in the technology sector advantages are rarely permanent and, in 2026, the position of the company led by Sam Altman It’s a far cry from what it had then.
Google has managed to attract the general public with Nano Banana Prowhile Gemini steadily gaining ground as an artificial intelligence chatbot. At the same time, ChatGPT’s market share has fallen significantly in some markets. Anthropic, for its part, has established itself as a reference in software engineering and has become one of the preferred tools among programmers.
In this race to set the pace of AI, this Thursday we witnessed a curious movement: the almost simultaneous arrival of two models focused on programming, GPT-5.3-Codex and Claude Opus 4.6. The coincidence does not seem coincidental and reflects the extent to which the major players in the sector compete to define the next step, in a scenario where the main beneficiaries are, once again, the users.
With these new models already on the table, the question becomes what they really contribute. There are plenty of promises and they are also beginning to appear benchmarks comparable that help to place them. So, therefore, it is time to look in a little more detail at what OpenAI and Anthropic propose for those who use AI as a development tool.
GPT-5.3-Codex and Opus 4.6 enter the scene: what each promises to developers
GPT-5.3-Codex is presented as a model focused on scheduling agents which seeks to expand the scope of what a developer can delegate to AI. OpenAI claims that it combines improvements in code performance, reasoning and professional knowledge over previous generations and is 25% faster.
With this balance, the system is oriented to prolonged tasks that involve research, use of tools and complex execution, while also maintaining the possibility of intervening and guiding the process in real time without losing the work thread.
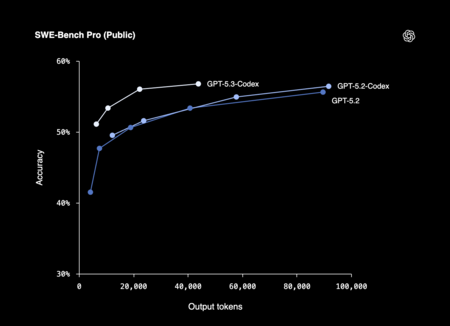
One of the most striking elements that OpenAI highlights in this generation is the role that Codex itself would have had in its development. The team used early versions of the model to debug training, manage deployment, and analyze test and evaluation results, an approach that accelerated research and engineering cycles.
Beyond that internal process, GPT-5.3-Codex also shows progress in practical tasks such as the autonomous creation of web applications and games. The company has published two examples that we can try right now by clicking on the links: a racing game with eight maps and a diving game to explore reefs.
Anthropic’s turn comes with Claude Opus 4.6, an update that the company presents as a direct improvement in planning, autonomy and reliability within large code bases. The model, they claim, can sustain agentic tasks for longer, reviewing and debugging its own work more accurately.
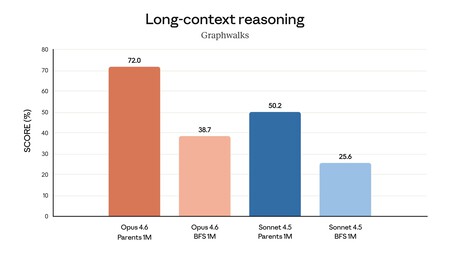
The idea is that we can use these capabilities in tasks such as financial analysis, documentary research or creating presentations. Added to this is a context window of up to one million tokens in beta phase, a leap that seeks to reduce the loss of information in long processes and reinforce the usefulness of the system.
Beyond the core of the model, Anthropic accompanies Opus 4.6 with a series of changes aimed at prolonging its usefulness in real workflows. Among them there are mechanisms such as the so-called “adaptive thinking”, which allows the system automatically adjust the depth of your reasoning depending on the context.
Configurable effort levels and context compression techniques designed to sustain long conversations and tasks without exhausting the available limits also appear on the scene. Added to this are teams of agents that can be coordinated in parallel within Claude Code and deeper Excel or PowerPoint integration.
While OpenAI’s product, GPT-5.3-Codex, is not yet available in the API, Anthropic’s is. Maintains the base price of $5 per million entry tokens and $25 per million exit tokenswith nuances such as a premium cost when the prompts exceed 200,000 tokens.
Measure who wins with numbers?
When trying to put GPT-5.3-Codex and Claude Opus 4.6 face to face, the main obstacle is not the lack of figures, but rather their difficult correspondence. Each company selects evaluations that best reflect its progress and, although many belong to similar categories, they differ in methodology, versions or metrics, which prevents a direct reading.
In this type of models, this fragmentation of results is part of the state of the technology itself, but also requires cautious interpretation that separates technical demonstrations from truly equivalent comparisons. Only from this filter is it possible to identify the few points where both systems can be measured under comparable conditions and draw useful conclusions for developers.
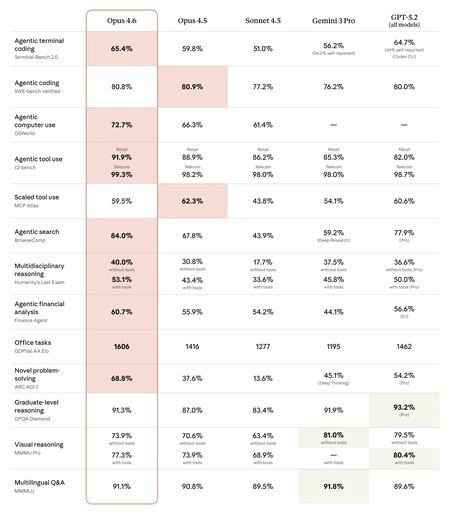
If we restrict the analysis to truly comparable metrics, the common ground between GPT-5.3-Codex and Claude Opus 4.6 is limited to two specific evaluations identified through our own research: Terminal-Bench 2.0 and OS World in its verified version.

The results show a distribution of strengths rather than a clear supremacy. GPT-5.3-Codex marks a 77.3% in Terminal-Bench 2.0 compared to 65.4% for Opus 4.6, which points to greater efficiency in terminal-centric workflows. On the contrary, Opus 4.6 reaches a 72.7% on OSWorldsurpassing the 64.7% of GPT-5.3-Codex in general interaction tasks with the system, a contrast that reinforces the idea of specialization according to the environment of use.
So we could say that the capabilities described by each manufacturer point to tools that are no longer limited to generating code, but rather seek to participate in prolonged processes of analysis, execution and review within real professional environments. This transition introduces new selection criteria that go beyond punctual performance.
In Xataka | OpenAI has a problem: Anthropic is succeeding right where the most money is at stake
GIPHY App Key not set. Please check settings