
There is a new star technique to train AI models super efficiently. It is at least what Alibaba seems to have demonstrated, that Friday presented His family of QWEN3-next models and did so presuming from spectacular efficiency that even Leave behind the one he achieved Deepseek R1.
What happened. Alibaba Cloud, the Alibaba group’s cloud infrastructure division, presented a new generation of LLMS on Friday that described as “the future of efficient LLMs.” According to those responsible, these new models are 13 times smaller than the largest model that that company has launched, and that was presented just a week earlier. You can try QWen3-Next On the Alibaba website (Remember to choose it from the drop -down menu, in the upper left).

QWen3-Next. This is what the models of this family are called, among which it stands out especially QWen3-Next-80b-A3Bwhich according to developers is up to 10 times faster than the QWEN3-32B model that was launched in April. The really remarkable thing is that it also manages to be much faster with a 90% reduction in training costs.
$ 500,000 is nothing. According to AI Index Report From Stanford University, to train GPT-4 OpenAI invested $ 78 million in computation. Google was further spent on Gemini Ultra, and according to that study the figure amounted to 191 million dollars. It is estimated that QWEN3-Next has only cost $ 500,000 in that training phase.
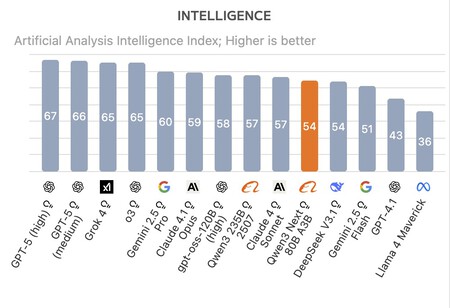
Better than its competitors. According to the benchmarks made By the artificial firm Analysis, QWen3-Next-80B-A3B has managed to overcome both the latest version of Deepseek R1 and Kimi-K2. Alibaba’s new reasoning model is not the best in global terms-GPT-5, Grok 4, Gemini 2.5 Pro Claude 4.1 Opus overcome it-but still achieves outstanding performance taking into account its training cost. How have you done it?
Mixture of experts. These models make use of the Mixture of Expert architecture (MOE). With it, the model is “divided” into a kind of neuronal subnets that are the “experts” specialized in data subsets. Alibaba in this case increased the number of “experts”: while Depseek-V3 and Kimi-K2 make use of 256 and 384 experts, QWen3-Next-80b-A3B makes use of 512 experts, but only activates 10 at the same time.
Hybrid attention. The key to that efficiency is in the so -called hybrid attention. Current models usually see their efficiency reduced if the input length is very long and have to “pay more attention” and that implies more computing. In Qwen3-Next-80b-A3B, a technique called “Gated Deltanet” is used that They developed and shared MIT and NVIDIA in March.
GATED DELTANET. This technique improves the way in which the models pay attention when making certain adjustments to the input data. The technique determines what information retain and which can be discarded. That allows creating a precise and super -efficient cost mechanism. In fact, QWEN3-Next-80B-A3B is comparable to the most powerful Alibaba model, Qwern3-235B-A22B-Thinking-2507.

Efficient and small models. The growing costs of training new models of AI begin to be worrisome, and that has made more and more efforts to create “small” language models that are cheaper to train, are more specialized and especially efficient. Last month Tencent presented models below 7,000 million parameters, and another startup called Z.AI published its GLM-4.5 Air model with only 12,000 million active parameters. Meanwhile, large models such as GPT-5 or Claude use many more parameters, which makes the necessary computation to use them much greater.
In Xataka | If the question is which of the great technology is winning the AI career, the answer is: None
GIPHY App Key not set. Please check settings