
To use Chatgpt In the cloud it is fantastic. It is always there, available, remembering our previous chats and responding quickly and efficiently. But depending on that service also has disadvantages (cost, privacy), And that is where a fantastic possibility enters: Execute AI models at home. For example, Assemble a local chatpt.
This is what we have been able to verify in Xataka when trying the New Open Openai models. In our case we wanted to try the GPT-Oss-20B model, which can be used theoretically without too many problems with 16 GB of memory.
That is at least what Sam Altman presumed yesterday, which after launch He affirmed That the upper model (120b) can be executed in a high -end laptop, while the smallest can be executed on a mobile.
Our experience, which has gone to trompicones, confirms those words.
First tests: failure
After trying the model for a couple of hours it seemed to me that this statement was exaggerated. My tests were simple: I have a MAC Mini M4 with 16 GB of unified memory, and I have been testing AI models for months through months Ollamaan application that makes it especially easy to download and execute them at home.
In this case, the process to prove that new “small” model of OpenAi was simple:
- Install Ollama In my Mac (I already had it installed)
- Term a terminal in macOS
- Download and execute the OpenAI model with a simple command: “OLLAMA RUN GPT-Oss: 20B “
In doing so, the tool begins to Download the model, which weighs about 13 GBalready then execute it. Throw it to be able to use it already takes a bit: it is necessary to move those 13 GB of the model and pass them from the disk to the unified memory of the Mac. After one or two minutes, the indicator appears that you can already write and chat with GPT-Oss-20B.
That’s when I started trying to ask some things, like that already traditional test of counting Erres. Thus, I started asking the model to answer me to the question “How many” R “are there in the phrase” San Roque’s dog has no tail because Ramón Ramírez has cut it? “

There GPT-Oss-20b began to “think” and showed his chain of thought (Chain of Thought) in a more off gray color. In doing so one discovers that, in effect, this model answered the question perfectly, and was separating by words and then break -in each word to find out how many erres there were in each one. He added them at the end, and obtained the correct result.
The problem? That was slow. Very slow.
Not only that: in the first execution of this model, two Firefox instances had open with about 15 tabs each, in addition to a Slack session in macOS. That was a problem, because GPT-Oss-20B needs at least 13 GB of RAM, and both Firefox and Slack and the background services themselves already consume a lot.
That made trying to use it, the collapse system. Suddenly my Mac Mini M4 with 16 GB of unified memory was completely hung, without responding to any bracket or mouse movement. I was dead, so I had to restart it to the hard ones. In the following restart I simply opened the terminal to execute Ollama, and in that case I could use the GPT-Oss-20B model, although as I say, limited by the slowness of the answers.
That caused that many more evidence could happen either. I tried to start an unimportant conversation, but there I made an error: This model is a reasoning modeland therefore try to always respond better than a model that does not reason, but That implies that it takes even more to respond and consume more resources. And in a team like this, which is already just starting, that is a problem.
In the end, total success
After commenting on the experience in X some Messages in x They encouraged me To try again, but this time with LM Studio, which directly offers a graphic interface much more in line with which Chatgpt offers in the browser.
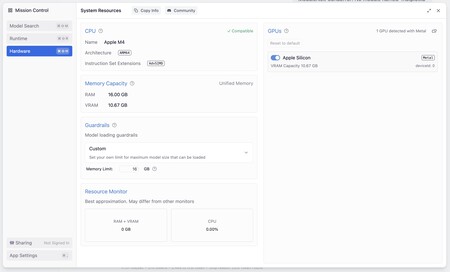
Of the 16 GB of unified memory of my Mac Mini M4, LM Studio indicates that 10.67 are dedicated to graphic memory right now. That data was key to use Openai’s open model without problems.
After installing it and downloading the model again I prepared to try it, but when I tried it, I gave me a mistake saying that I did not have enough resources to start the model. The problem: the assigned graphic memory, which was insufficient.
When navigating the application configuration I proved that unified graphic memory had been distributed in a special way, assigning in this session 10.67 GB to graphic memory.
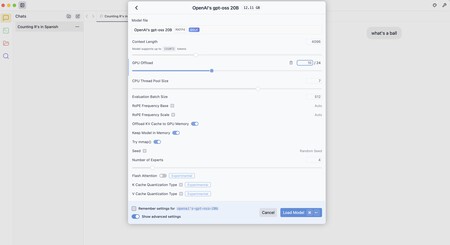
The key is to “lighten” the execution of the model. For this it is possible to reduce the level of “GPU offload” – how many layers of the model are loaded in the GPU. The more we load faster, but also more graphic memory consumes. Locating that limit in 10, for example, was a good option.
There are other options such as deactivating “Offload KV Cache to Gpu Memory” (cachea intermediate results) or reduce the “evaluation batch size”, how many token are processed in parallel, which we can download from 512 to 256 or even 128.
Once these parameters were established, I got the model finally charged in memory (it takes a few seconds) and being able to use it. And there the thing changed, because I met a chatgpt more than decent that he answered quite quickly to the questions and that was, in essence, very usable.
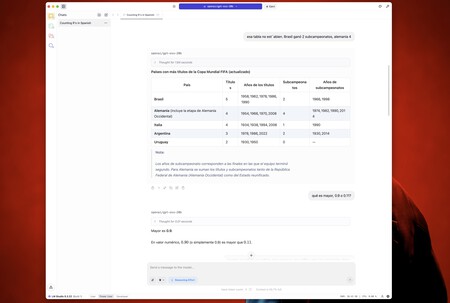
Thus, I asked him about the problem of the Erres (he replied perfectly) and then I also asked that he made a table with the five countries that most championships and runners -up in the world of football have won.
This test is relatively simple —The correct data They are on Wikipedia– But the IAS are wrong again and again and this was no exception. Some years were invented For some countries and changed the number of runner -up even when I asked him to review the information again.
Then I wanted to try something different: that it would generate a Small code in Python to create a graph from some starting data. He told me that I had to install a bookstore (MatploTlib), and then generated the code for the graph.
It should be noted that this version of “local chatpt” does not generate images, but Yes can create code that generates graphicsfor example, and that is what I did. After executing that code in the terminal, surprise. As you will see something later, the result, although somewhat raw, is sorpendent (and correct).
The truth is that the performance of the local AI model has surprised me very pleasantly. It is true that you can make mistakes, but How do Openai engineers promise The performance is very similar to that of the O3-mini model that remains a great option even when using it in the cloud.
The answers are usually really decent in precision, and the failures that you can have and what we have seen – the tests have been limited to a few hours – are in line with other latest generation models that are even more advanced and demanding in resources. So, more than pleasant surprise In these first impressions.
Memory is everything
The initial problem with our evidence reveals a reality: Openai’s statement and Sam Altman has a small print. The announcement talks about two variants of their open models of AI. The first, with 120,000 million parameters (120b) and the second with 20,000 million (20b). Both can be downloaded and used for free, but as we indicated, there are certain hardware requirements to do so.
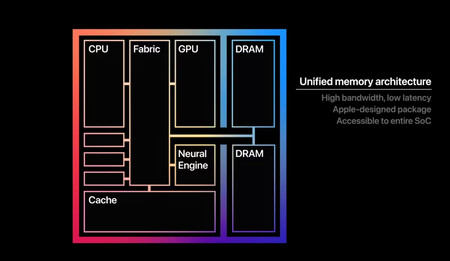
The unified Apple chips has become its great advantage when executing local AI models. Source: Apple.
Thus, to be able to execute these models on our teams we will need above all a certain amount of memory:
- GPT-Oss-120B: At least 80 GB of memory
- GPT-Oss-20B: At least 16 GB of memory
And here the critical detail is that those 80 GB or 16 GB of memory should be, be careful with this, of graphic memory. Or what is the same: to be able to use them with ease we will need at least that amount of memory in our dedicated or integrated GPU.
While PCs use RAM on one side and graphic memory (in the GPU, much faster) on the other, Apple MACs make unified memory use. That is, they “combine” both types and “unify” being able to use that memory interchangeably as the main memory or as a graphic memory.
That unified memory has a performance that He is on horseback between the conventional RAM used on Windows PCs and the one that is present in the latest generation graphics cards.
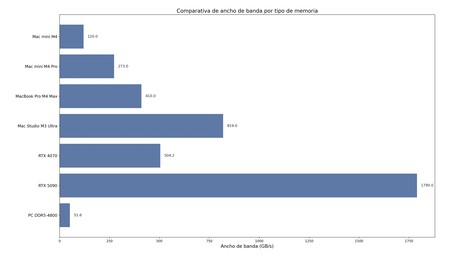
Bandwidth of different types of memory systems. The graph has been generated through a small code in Python generated by GPT-Oss-20B.
To get an idea, the bandwidth of some Apple chips (with similar unified memory systems, but more and more powerful according to the chip) and RAM memories and conventional graphics is approximately the following:
- Apple Mac Mini M4: 120 Gb/s (1)
- Apple Mac Mini M4 Pro: 273 Gb/s (1)
- Apple MacBook Pro M4 Max: 410 GB/S (2)
- Apple Mac Studio M3 Ultra: 819 GB/S (3)
- NVIDIA RTX 4070: 504.2 GB/S (4)
- NVIDIA RTX 5090: 1,790 GB/S (5)
- PC with RAM DDR5-4800: 51.6 GB/S (6)
As can be seen, in a current PC, RAM is much slower than in the most advanced Apple chips. The MAC Mini M4 that I have used in the tests is not especially remarkable, but the bandwidth of its memory is double that of DDR5-4800 modules. Here, by the way, it is where we mentioned above we have used our “local chatgpt” to generate a graph from a small code in Python. The result, without being especially colorful, is functional and correct.
In the end, the idea after the graph is precisely to reflect the most important thing when executing local AI models. The GPU and the NPU certainly help a lot, but the key is in 1) How much graphic memory we have and 2) What bandwidth does that graphic memory have. And in both cases, the more, much better, especially if we want to run heavy models at home, Something that can leave very, very expensive.
The GPT-OS-120B model, for example, would require at least 80 GB of graphic memory, and there are not many teams that can boast something like this: here the unified memory scheme of Apple is an option for now winner, because the alternative is to use one or several high -end dedicated graphics To use local models with low Windows or Linux.
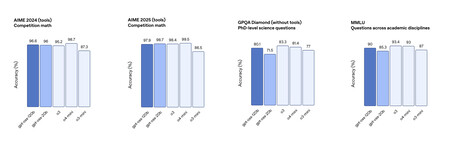
Various benchmarks reveal that these open models are at the level of O3-mini and not far from O4-mini in some tests. Source: OpenAi.
That said, it will be interesting to see where these models end up moving. The statement that the smallest model (GPT-Oss-20B) can be used in mobile phones is something risky, but not crazy: with an adequate configuration of the execution layer (Ollama, LM Studio, or the corresponding mobile app), it seems perfectly feasible that we can have a local chatpt on our mobile.
One that allows all our data not to leave (privacy by flag) and that also allows us to save on costs. The future of the local AI opens up now more than everand we only hope this becomes a trend for other companies that develop open models. This one of OpenAI is undoubtedly a great and promising step for that future theoretical in which we have models of the executing massively on our PCs, in our mobiles … or in our glasses.
In Xataka | Goal has an excellent reason to launch a gigantic flame variant 4: Specialization capacity
GIPHY App Key not set. Please check settings