
The great IAS we use daily like GPT, Gemini, Claude, Perplexity and Company exist and are able to do what they do thanks, in large part, in large part, to the content available on the Internet. Companies such as Openai, Google and Anthropic, to mention some, have tracked (and track in real time) the web in search of content that answers the user’s questions.
And they do it, unless there are specific agreementswithout offering consideration to the creators of said content beyond a link. It is a practice that is in question from the birth of this technology. Blog articles, Wikipedia, books, User generated content, even personal data. The trackers, those automated bots, do not leave anything behind and today Cloudflare has said that it is over
From today, Cloudflare will block by default Scrapers of AI, something that has more implications of what it might seem. Let’s start at the beginning.
Web Crawlers. This technology is not new and, in fact, it is thanks to it that the foundations on which the Internet is based (the web search) exists. Surely it is familiar about “The Google Spider“, that bot that tracks the entire website in search of content to index and offer the user. It is only one of the thousands and thousands that exist and that generate 30% of all traffic worldwide.
This technology was capital to shape the Internet we know and the relationship with content generators was symbiotic. The economy of the click was born: the creator generates a content, Google Lo Indexa, the user finds it through Google, Google generates income with the advertising of the search engine, the creator receives free traffic and generates income thanks to advertising, affiliates, etc.
With AI, the movie is quite different.
Data. The AI models need information to feed, be trained and be able to answer questions. To do this, the big companies that we all know tracked the website, They extracted all the content they could and used it to develop technologies such as Chatgpt. What is the problem? That content could be protected by copyright, which led to the fact that The New York Times sue Openai For this same reason since the companies of AI had to sign agreements with the means to access their content.
Image: Solen Feyissa
Ias connected. AI was evolving and, as expected, It ended up connecting to the Internet. Not only did he give answers based on finite training data, but could be connected to the network to search for the response in the media, blogs and online pages in real time (or almost in real time). The user no longer had to click on a link. The AI searched, analyzed and generated the answer, making traffic towards the media and blogs.
The user no longer accesses the original content, does not click on the links. Instead, it consumes a derived product generated by AI
To this technology the Ai Crawlers or what is the same is given life: the trackers ia. They are the digievolution of the bots that shape the Internet we know. Among them are OPENAI GPTBOT, META-EXTERNALAGENT META, CLAUDEBOT OF ANTHROPIC O BYTESPIDER DE BYTEDANCE. With them the symbiotic relationship that we mentioned above begins to deteriorate because the user no longer accesses the original content, does not click. Instead, it consumes a derived product generated by Ia.
The biggest example: new previous views generated with AI that appear on Google every time you do any search.
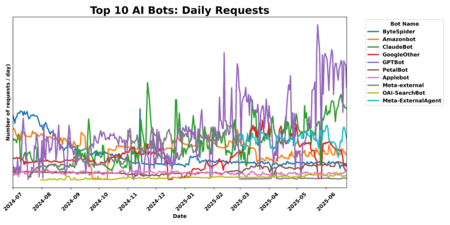
Volume of daily requests of the main AI Bots | Image: Cloudflare
Put the brake … or not, I’m just a .txt. How to solve this indiscriminate tracking and without consideration? The first proposal was Update the Robots.txt file to indicate to the bots that cannot extract the content of a website. This file and one of the most used resources to administer the activity of the bots, but has a small problem: its compliance is voluntary. IA companies can follow the instructions, or can ignore and extract the content.
In addition, it may happen that we touch what we should not and that our website disappears from Google. Every website who wants to be on Google must allow Googlebot, its spider, to indicate to the bots that cannot extract the content of a website. This file is one of the most used resources to administer the activity of the bots, but it has a small problem: its compliance is voluntary. IA companies can follow the instructions, or can ignore and extract the content.

Cloudflare is planted. We arrive at the recent announcement made by Cloudflare. The platform (The middle internet depends on) has announced that, from today, the blockade of the AI Crawler will be active by default. To do this, Cloudflare offers direct management of robots.txt to avoid problems such as the aforementioned. The key, of course, is that Cloudflare will be in charge of maintaining the updated blockages according to the IA panorama. This, although it is activated by default, is voluntary and can be completely deactivated in the adjustments.
To pay. Cloudflare’s other proposal is Pay per crawl. Since AI will continue to need access to the content of a website, why not give the creator the option to charge for such access? Pay Per Crawl, which is currently in Beta, allows domain owners to define a fixed price at request. If an AI Crawler wants to extract the content of that domain, you will have to pay for it. On paper, this tool has the potential to change the current panorama, but everything will depend on the scope, its adoption and what measures take the tracker operators.
Cover image | Solen Feyissa
In Xataka | I have asked the AI any bullshit and now I am writing a news about her
GIPHY App Key not set. Please check settings