Pokémon Go brought millions of players to the streets. Millions of players who were actually training an AI

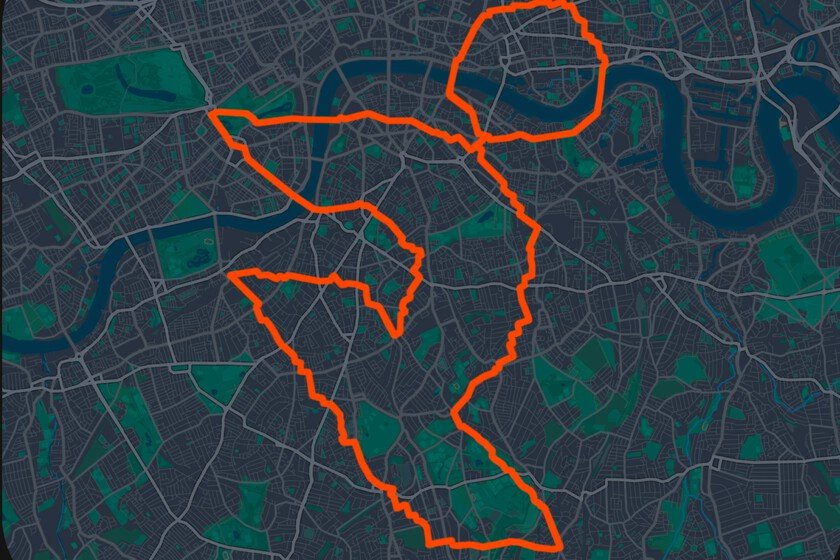
In 2016 it came to the mobile market Pokémon Goa spinoff of the popular entertainment franchise with a very interesting premise: capture Pokémon in your city using your cell phone’s GPS. The game caught on very quickly and became a phenomenon. It’s been almost 10 years since that and Niantic, its developer, has taken advantage of all the data that millions of players have been giving them to guide delivery robots through the cities. Your first client: Coco Robotics. The business that no one saw coming. The amount of information that can be obtained from Pokémon Go is truly impressive, since millions of people have voluntarily traveled the world with their mobile phones in order to capture (digitally) this type of creatures. And each game leaves an invisible trace, since there are millions of photos of buildings, squares and streets labeled with very precise coordinates that would not have been possible without the information provided by its users when playing. Five hundred million people installed the app in its first 60 days, according to Brian McClendonCTO of Niantic Spatial. Eight years later, the game still has more than 100 million players in 2024, according to data from Scopely, the company that acquired Pokémon Go from Niantic that same year. The problem that GPS does not solve. GPS devices become a bit silly when they have to operate on sidewalks and much of the urban fabric that does not correspond to the road. Signals bounce between skyscrapers, tunnels and viaducts and the margin of error can be up to 50 meters, enough to place a robot on the wrong sidewalk or the next street. “The urban canyon is the worst place in the world for GPS,” affirms McClendon. Coco Robotics, a startup that operates nearly 1,000 delivery robots in cities such as Los Angeles, Chicago, Miami and Helsinki, knows this well, as its devices operate precisely in those dense areas where the signal is never reliable. This is where Niantic Spatial comes in. In May 2024, Niantic separated its spatial and artificial intelligence division. created Niantic Spatial as an independent company. Its core product is a visual positioning system (VPS) trained with 30 billion urban images, capable of placing a device on the map with a precision of a few centimeters from a handful of photos of the environment. The key is that these images come from millions of points of interest in Pokémon Go and Login (the company’s pre-Pokémon Go AR game, released in 2013). In such popular games, players have for years been directed to photograph the same place from different angles, at different times and in different weather conditions. “We had over a million locations around the world where we can locate you to the nearest centimeter and, more importantly, know where you are looking,” explains McClendon. What this changes for robots. Coco Robotics has been the first partner to adopt this technology. Its robots, equipped with four cameras, will combine conventional GPS with Niantic Spatial’s VPS to position itself more accurately, especially in pickup areas in front of restaurants and in delivery to the customer’s door. According to Zach Rash, CEO of Coco, the goal is meet delivery times promised and not depend on margins of error that in practice mean arriving late or to the wrong place. The model already solves one of the most practical challenges of urban robotics: performing well where conventional systems fall short. Beyond the distribution. John Hanke, CEO of Niantic Spatial, talks about what he calls a living map: a hyper-updated simulation of the real world that updates as robots move through it and provide new data. The idea is not only that the maps are more accurate, but that they are designed for machines, not people. This involves adding descriptions of each element of the environment, its properties, its context. “This era is about building useful descriptions of the world for machines to understand,” says Hanke. In that sense, Niantic Spatial differs from other bets on world models, such as those of Google DeepMind or World Labswhich focus on generating virtual environments. Niantic Spatial wants to replicate the real world as it is. In Xataka | OpenClaw changed the rules of the AI race. Technology companies already have their answer: copy it