
The Chinese giant Alibaba has announced a new language model, the largest they have announced to date. It is called Qwen-3-Max and presumes that it has more than 1 billion parameters.
The biggest. It is the last model within the series Qwen3 which was launched in May of this year and, as its name ‘Max’ indicates, it is the largest to date. Its size is given by the parameters, 1 billion to be exact, while the previous models of its series reached a maximum of 235,000 million. According to South China Morning Post (Which owner Alibaba), his model stands out in understanding of language, reasoning and text generation.

Benchmarks. The results of the benchmarks place QWen3-Max ahead of competitors such as Claude Opus 4, Deepseek v3.1 and Kimi K2. If Gemini 2.5 Pro or GPT-5 does not appear, it is because they are models of reasoning and have only compared rapid response models. As they point out in Dev.toboth Gemini 2.5 Pro and GPT-5 obtain higher scores in mathematics and code, so reasoning models continue to have advantage in those areas. Qwen3-max-preview can already be tested free of charge.
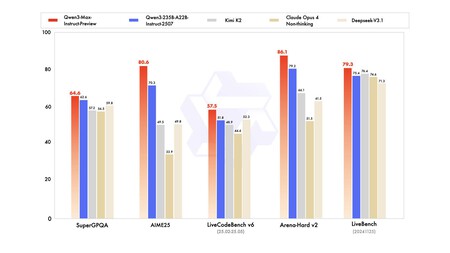
Benchmarks shared by Alibaba.
Parameters. The parameters are all the internal variables that a model learns during training. In other words, it is the knowledge that the model has obtained from the data with which it has trained and allows it to interpret our requests and generate their answers. In theory, the more parameters, the model will have more and better capabilities. It also implies that it needs more computational power both to train and to execute the model.
More does not mean better. The speech of the parameters remembers that of the megapixels with the first cameras. A 100 megapixel sensor will take larger photos than a 10 sensor, but there are other crucial factors that affect image quality such as sensor size or lens luminosity.
Quality data. More parameters can be translated into more learning capacity and more resolution of complex tasks, as long as quality training data has been used. It is obvious: a language model that has been trained with redundant, incorrect or biased data will learn and continue to reproduce those errors in their operation.
There are more. In 2022, the laboratory Deepmind from Google, discovered that many models were oversized in parameters but underlined in data. To demonstrate it they created the Chinchilla model with “only” 70,000 million parameters, but four times more data. The result was that it beat Gopher, a model with four times more parameters.
Architecture. The architecture of the model is another decisive factor in order to achieve an efficient model; A standard architecture is not the same that forces the model to use its entire neuronal network, than one like Mixture of experts which consists of many smaller networks. It would be something like having an expert committee each with a specialty. In this way, the model can choose your expert for each query and not have to use the entire network. For example, with this technique, Mistral manages to use only a fraction of his parameters And so it is faster and cheap to execute.
Image | Markus Winkler, via Pexels
GIPHY App Key not set. Please check settings