
We didn’t expect it so soon, but here is Claude Opus 4.8the new version of Anthropic’s frontier model. Only 41 days have passed since release of Claude Opus 4.7which seems to make it clear that the company was not entirely happy with said model, which did not end up getting very good reviews either. With Claude Opus 4.8 the really curious thing is not that it once again sets records in most benchmarks. The surprise is his honesty.
It’s better, yes, but it’s not what matters. In the internal results of the benchmarks published by Anthropic it is clear that Opus 4.8 is above Opus 4.7, but also GPT 5.5 and Gemini 3.1 Pro (curious, they do not compare it with the recent Gemini 3.5 Flash. It surpasses all of them in those tests except in TerminalBench 2.1, in which GPT-5.5 is somewhat superior. It is actually expected that each new model surpasses its predecessor, but what is striking here is the approach of the model.
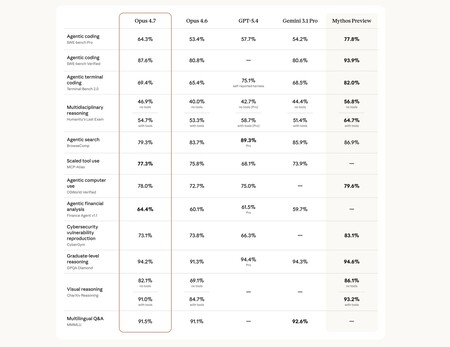
Honesty above all. Boris Cherny, head of Claude Code at Anthropic, explained that the model not only programs better: “it is significantly more honest about its own work. It tells you when it is unsure about something and detects its own failures instead of declaring victory too soon.”
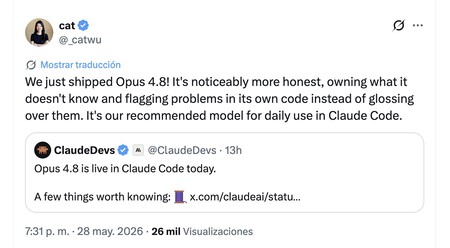
I only know that I don’t know anything. Another Anthropic engineer, Catherine Wu, influenced in that new “personality” of Claude Opus 4.8, who is capable of admitting that he does not know something instead of answering for the sake of answering and overlooking errors in his answers or in the code he generates. Those who have tried it match in that it is a more “aligned” model, that is, one that adjusts to human values, intentions, ethics and objectives.
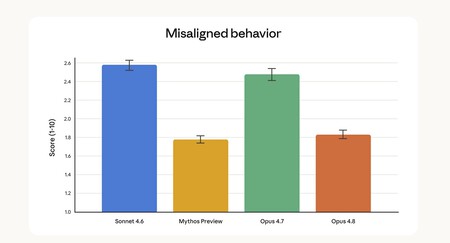
Less hallucinations, more humanity. For some time we have been seeing how new AI models are better in benchmarks, but there have also been significant jumps in the reduction of hallucinations. Not only do they invent and make fewer mistakes: they begin to recognize that they don’t know everything. That is very important… and very human. The very complete “System Card” It includes numerous metrics that certainly seem to demonstrate that we are facing a much more polished model than its predecessors in this area.
Workflows. One of the new features presented along with the model are the dynamic workflows (Dynamic Workflows), which are available in preview and are aimed at one thing: being able to work with more complex tasks in Claude Code. Thanks to this option it is possible to deploy hundreds of parallel agents in a single session, something for example useful for analyzing and migrating code repositories of hundreds of thousands of lines.
No Sonnet and Haiku. Claude Sonnet 4.6 was released on February 17, 2026, but Anthropic has not updated this model since. Things are even worse for Claude Haiku, whose latest version is 4.5, released on October 15, 2025. These models were more modest versions in terms of performance but much cheaper (especially Haiku), and so far Anthropic has not updated them. That benefits their interests, because if you want the best, you can only have the best and the most expensive, but not the best in its “affordable” version.
Mythos Capability Models Coming Soon. In the official Anthropic announcement they made it clear that “Users will detect that Opus 4.8 is a modest but tangible improvement over its predecessor”, but they also pointed out something important, and that is that in the coming weeks we will have AI models with capabilities similar to Claude Mythos, but publicly available:
“We plan to launch a new class of model with even greater intelligence than Opus. As part of Project Glasswing, a small number of organizations are currently using Claude Mythos Preview for cybersecurity work. Models with this level of capability require more robust cybersecurity measures before their general release. We are making rapid progress in developing these measures and look forward to offering Mythos class models to all of our customers in the coming weeks.”
GIPHY App Key not set. Please check settings