
A few days ago, the Chinese company Moonshot AI launched Kimi K2.6its new LLM that competes with the Gemini, GPT and Claude model families and is also especially competitive in price. Weeks earlier, it had launched Kimi Code, a programming AI agent that in turn competes with Gemini Cli, Codex and Claude Code. The question is obvious: can the Kimi Code/Kimi K2.6 pairing really compete with the fashionable pairing, Claude Code/Opus 4.7? The answer is complicated.
A great model (but not perfect). Kimi K2.6 is an open weights model with one trillion parameters in total (an American trillion), of which 32 billion parameters are active and which uses the well-known Mixture-of-Experts architecture. In it launch article Its performance is shown compared to that of GPT-5.4 and Opus 4.6 and the truth is that its numbers in these synthetic tests seem really excellent:
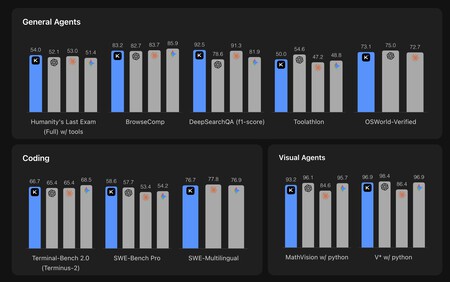
Here Kimi K2.6 is compared to GPT-5.4, Claude Opus 4.6 and Gemini 3.1 Pro. Source: Moonshot AI.
Up to 8 times cheaper than Opus 4.6. Has subscription plans Claude Pro or ChatGPT Plus style, but it can also be used via API. The price in that case is $0.60 per million input tokens (0.16 if cached) and $4 per million output tokens. Claude Opus 4.6 costs $5 per million input tokens and $25 per million output tokens, or up to eight times more. Claude Opus 4.7 It has the same price and is theoretically better in performance, but when Kimi K2.6 was announced this version had not yet appeared (nor GPT-5.5).
The magic of the swarm of AI agents. Claude Code works sequentially. Analyze the problem, execute a step, check the result and decide how to proceed. In Kimi Code a different approach is used: a “master agent” divides or decomposes the task we ask of it into independent subtasks and from that division launches up to 300 “subagents” that run in parallel and are capable of coordinating up to 4,000 steps simultaneously.
Are many working at the same time better than one? It is the so-called “swarm of agents” of Kimi K2.6 that is used to the fullest in Kimi Code and that we can also activate in its free version on its official website. In Kimi K2.5 up to 100 subagents and 1,500 steps could be launched, so the jump is significant. In internal tests, Moonshot showed how these swarms managed, for example, to “refactor” an open source financial engine, working 13 hours straight and making more than 1,000 tool calls with a 185% improvement in average performance. Of course, these were internal tests.

Beyond benchmarks. Kilo.ai is a company that develops tools like Kilo Code or Kilo CLI—programming agents similar to Kimi Code—and its engineers wanted evaluate the performance of both combinations. They gave Claude Opus 4.7 and Kimi K2.6 the same 1,042-line prompt to create FlowGraph, a workflow orchestration API with directed graph validation or real-time event streaming. Both models ran on Kilo CLI because what they wanted to compare were the models without further ado.
Kimi was cheaper, but he also failed more. Claude Opus 4.7 finished in 20 minutes and the final cost was $3.56. Kimi K2.6 took longer, partly because server availability was limited (the model had just been launched), but it cost $0.67. Five times less.
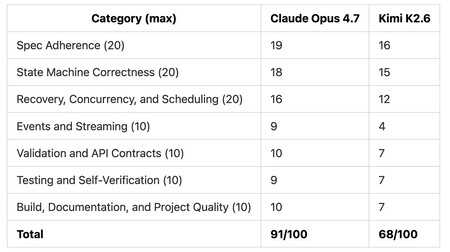
Kimi K2.6 did it well at a ridiculous price. Claude did much better, but it also cost five times as much.
Kimi did 75% of what Claude did at 19% of the cost. The problem is that both believed they had done everything right and did not detect if they had made mistakes. Further analysis revealed that Claude had committed one and that Kimi had committed six of varying importance. According to Kilo.ai analysts, the final score for both was 91 points out of 100 for Opus 4.7 and 68 points out of 100 for Kimi.
Two ways to see the glass. That score seems to make it clear that Kimi is simply cheaper because he did a worse job. But Kilo engineers had another way of looking at it. They have been comparing open weight models of Chinese companies for some time and have noticed how the gap with the “frontier” models of Anthropic or OpenAI is becoming less and less pronounced.
“With a price of $0.67 and a thorough review, Kimi K2.6 is now a viable option. With a price of $3.56 and fewer fixes needed, Claude Opus 4.7 is the safer option. The choice between the two options depends on the analysis. A year ago, this choice was practically non-existent at this level of complexity.”
Review is mandatory. Or what is the same: if after the work of Kimi K2.6 one carried out a more in-depth review and correction, it is likely that all these errors would be detected and corrected, but if we had to trust both models and we could only execute “one pass” of AI execution, Opus 4.7 would win the game. The key is that: one should not trust the code of any model right away, and it is advisable to always review that code.

The geopolitical factor. Kimi and Kimi Code come from China, and the startup Moonshot AI has financial backing from Alibaba. The code that is processed in these models passes through their servers, something that for an individual developer may be irrelevant. However, for a company with sensitive proprietary code, contracts that must comply with certain European or American regulations and projects in regulated sectors, this can be a significant obstacle. Kimi Code mitigates this problem by offering the possibility of running the model locally thanks to its open weights, but that requires very powerful machines and eliminates part of the cost advantage.
What Kimi Code has that Claude Code doesn’t. The clearest difference between both programming AI agents is parallelism. As we said, the ability to launch up to 300 subagents to work simultaneously attacking the same problem at the same time is remarkable. For analysis of large repositories or generation of massive documentation, this difference in speed is real and striking. There is another important element: Kimi Code is model agnostic, and allows the use of cloud models such as Claude, GPT or Gemini, but also local models via Ollama. Claude Code also accepts other models, but it is something more complicated use it with anything other than Sonnet/Opus.
Conclusion: long live the options. Here it is clear that what internal benchmarks say is very different from what real experiences say. The Kilo.ai comparison is striking and once again confirms two things. The first, that Claude Opus 4.6/4.7 is still superior to open weight models from Chinese companies. The second and most important, that it is no longer so superior. The performance gap narrows, but as it does, the cost aspect comes into play: whether the “Chinese model” is good enough for you (and it is becoming more so), what you will achieve is save a lot of money. Anthropic, OpenAI or Google should worry.
Image | Chris Ried
In Xataka | DeepSeek promised them happiness as the great Chinese AI. I didn’t count on a small detail: Kimi
GIPHY App Key not set. Please check settings