
AI does not seem to advance much. At least the “big” AI. The best market models are barely managed to make relevant qualitative leaps, and that despite being gigantic and the money, time and talent that companies invest in creating them. We have seen it with Call 4Claude 4 or the recent one (and disappointing) GPT-5. But while Esots gigantic models are less and less surprise, diminutos models are getting more and more. Something (small) is moving.
Google moves file Fichita. Last week Google surprised us all with the launch of a small AI model. Well, not: tiny. It could almost be said that it is a “nanomodel”. Gemma 3 270m It is an extremely compact version with only 270 million parameters. How small is that? It is easy to understand when we compare that model with one of the most reputable Open Source models:
- Call 4: In its Behemoth version, 288b (1,066 times larger)
- Qwen 3 235b (870 times bigger)
- Deepseek R1 671B (2,485 times larger)

A hyperefficient model. Google’s own ones made it clear that this model cannot compete with the great AI models, but that was not their goal. Its objective is to be hyperefficient and, attention, hyperspepecific. What is pursued here is to turn Gemma 3 270m into the pillar of many models adapted to very specific and concrete tasks.
The secret is called fine adjustment. GEMMA 3 270M, insisted these engineers, is a perfect model for fine adjustment processes (Fine Tuning) in very specific tasks. A company (or developer) anyone can take a small model, like this, and train it with their own data and refine it For a specific task following Google instructions For Hugging Face. For example, for generate stories to read children at night (code), to convert confusing text into structured data, to Customize messagesto classify emails or support tickets, or even for Play chess decently.
Small models to power. Google already opted for this type of small models when GEMMA presented 3 In March. At that time the versions presented were 1b, 4b, 12b and 27b, being the last one really “great” in absolute terms. The rest could be executed at local in machines with 16GB of graphic memory, such as a Mac Mini M4. It is precisely what we could check with GPT-Oss-20B (the download is about 12 GB), the Open Source model recently launched by OpenAi that behaved remarkably. But even the latter could be considered “great”, and in recent weeks and months we have seen more and more “tiny” models that encourage the market.
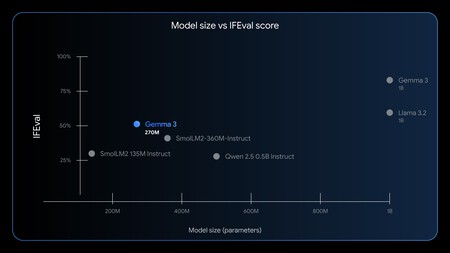
Gemma 3 270m’s performance is surprising despite its small size. And yet, the best of all is not that: it is his ability to adapt it to a specific task.
Examples everywhere. Microsoft has already opted for this type of models with Phi-3 and Phi-4 (14b), which in its launch competed with the Chinese model QWEN-2.5-14B, although these models again tried to raise “mini” alternatives to large models such as GPT-4O or call-3.3 70b. They could be used for fine adjustment, but they were already trained to adjust to various scenarios. Others, more unknown, have gone further: the startup liquid launched A model aimed at visual environments called LFM2 with only 440m parameters, and Nvidia has just launched Nemotron -Nano -9bthat achieves improve QWEN3-8B performance in various benchmarks.
Perfect for mobiles and smart watches. Another advantage of these models is that thanks to their small size are able to run on many more devices, however modest. They are ideal to be able to be used for example in our mobiles, smart watches or even more limited products. Its efficiency is the order of the day: how Google highlightedin a pixel 9 pro a quantized version (int4) of Gemma 3 270m can manage 25 “conversations” (chats) using only 0.75% of the mobile battery. It is so small that it can even be executed in a browser tab as if we load a website (heavy) more, such as the example of the web application that generates sleeping stories to children or This other which shows us how the model begins to break, but in a fun way, and whose code is available.
A promising future. The Google model, like similar ones, raises that other side that Google spoke. More than an off -road model, what they offer is a base on which to build “the right tool for work.” These types of small models, well refined and trained, can be the basis of the design of all types of small applications and AI agents that then end up interconnecting and that function very, very efficiently. Perhaps it was true that the best essences are sold in small bottles.
Image | Amanz
In Xataka | If the question is which of the great technology is winning the AI career, the answer is: None
GIPHY App Key not set. Please check settings