
I fondly remember that time in which Intel and AMD fought to create the first CPU capable of reaching 1 GHz clock frequency. That race AMD won it (surprise!)but until that milestone occurred the pace was dizzying. Or so it seemed to us, because with AI the pace of launches is absolutely crazy.
What a few weeks we’ve had, dear readers. Let’s see:
- January 27: Kimi.ai lance Kimi J2.5
- February 5: Anthropic lance Claude Opus 4.6
- February 5: Same day OpenAI lance GPT-5.3-Codex
- February 5: Kuaishou lance Kling 3.0
- February 12: Z.ai lance GLM-5
- February 12: ByteDance lance Seedance 2.0
- February 12: MiniMax lance MiniMax 2.5
- February 16: Alibaba lance Qwen3.5-397B-A17B
- Coming soon: DeepSeek v4, Does it call?, Gemini 3.1, …
The pace is absolutely frenetic, and the LLMs that a few years ago months weeks seemed to be fantastic now they are not so much. The new versions of these language models do not stop evolving, and AI companies continue to constantly offer new developments. Almost dizzying.
That, of course, has its good side and its bad side. We end 2025 with a certain boredom in the face of an AI that promised a lot but ended up changing hardly anything. Only at the end of the year was a palpable revolution seen with that spectacular combination formed by Claude Code and Opus 4.5.

The Anthropic binomial amazed the developers, who for the first time seemed to agree when it came to declaring that with this type of platform they could ask the AI for whatever they wanted, and that it would program it for you at once and almost always without problems. Of course there was some exaggeration in that speech, but certainly the capacity of Opus 4.5 and the degree of autonomy and Claude Code’s versatility They seemed to mark a turning point.
Then OpenClaw arrived and that expectations for AI agents have once again skyrocketedbut in parallel we are seeing a real fever of launches of new generative AI models, both in video (Kling 3.0 and especially Seedance 2.0 They have been viral phenomena in themselves) as in text/code. And with each new model, the promise of performance surpassing the previous generation. At least, of course, in the benchmarks.
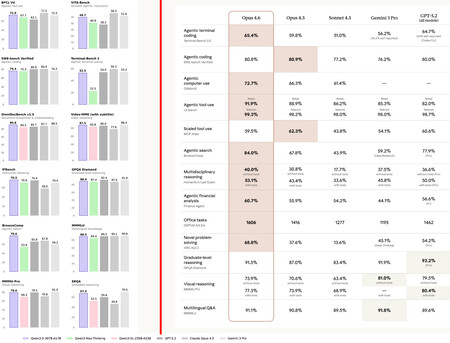
On the left, Alibaba’s internal benchmarks for Qwen3.5. On the right, those from Anthropic for Opus 4.6. Each one compares himself with whoever he considers appropriate.
Those bar graphs in the image above have become a constant, especially when the model is launched by a Chinese company. If the launcher is OpenAI, Google or Anthropic, tables are preferred. Be that as it may, the result always leads us to the same thing: each model is better than its predecessor and, normally, than many of the competition.
AI Subscription Fatigue
The problem with this is that this race never seems to end, and a model that seems fantastic today is not so great tomorrowwhen its competitor can barely outperform it, but it can also be considerably cheaper – Chinese models usually are – or offers other advantages such as larger context windows so that we can enter longer and longer texts – for example, large code repositories – as part of the prompt.
And of course, that poses a problem for users. If Opus 4.5 was so good, one could sign up for the Pro or Max plan and pay a year in advance, but that is a priori risky, because although you will have access to new models when you release them, you will have dedicated your investment in AI subscriptions to the Anthropic model without having as much room to try those of rivals.
Here short subscriptions are required: Subscribe to one model for one month so that I have some leeway in case I want to try another model the next month (or try two or three models in the same month, which is also a common case).
The prices of subscriptions to AI services are also not facilitators of these multiple tests. The normal thing is to pay 20 euros for a one-month subscription, and although Chinese models are usually much cheaper, they are also usually one step behind in capacity if one needs maximum performance.
But here the problem is repeated again and again: if I subscribe now to GPT-5.3-Codex, which everyone says is fantastic, how long do I pay for it, one month? Or do I also subscribe to GLM-5 to try, and next month I will try Opus 4.6 and MiniMax 2.5?

All of these decisions are difficult because the perception of each model depends on each user. Each of them has their needs, their budget and their own experiences with each model, so as much as the benchmarks say one thing, With AI models it is happening to us like with wines: No matter how much they tell us that one is better than the other, we perceive them in a very personal way.
And this frenetic advance also means that the expectation for models that really make a difference has been recovered. Vibe coding is not perfect, but it solves our needs better and better, and the same goes for AI agents like OpenClaw, which with their lights and shadows demonstrate that the future in which we have an AI employee—although at first they may be somewhat clumsy—working 24/7 does not seem to be that far away.
These are dizzying and fascinating times for AI. Again.
Image | Mohammad Rahmani
GIPHY App Key not set. Please check settings